
I Had Near 100% Test Coverage. It Didn’t Matter.
You cannot test for what you never described.

I woke up and saw a wall of emails in my personal account. Then logged into my corporate Slack, and it was filled with Zendesk messages from customers. Everyone was looking for me.
The library I wrote, jsonparser, which got used by a lot of projects, got its very own public CVE. So everyone started freaking out looking at their scanners.
“That’s what the fame is,” was my first thought.
Now I remember some notifications I kept ignoring from the Google OSS Fuzz project, I signed up multiple years ago.
This lib was written in the pre-AI-agents era (so weird to say that now!). Every piece was handcrafted manually, using best practices, with full test coverage.
I checked the function which had the issue, and it literally had near 100% test coverage. But it did not matter, because the issue was in handling of malformed input data. One of the edge cases which was missed. In other words, the issue was in the specification of what this function should do and how it should behave in edge cases.
But it opened one more can of worms. I wrote this library like 6 years ago. I don’t remember anything. And my only source of truth is the code and the tests, which is rather cryptic and looks more like archaeology.
The issue is fixed now. But how do I prevent such issues happening in the future? And if 100% code coverage is not the answer, what is? And what is my source of truth?
So I started digging. And it went way deeper than I expected, and changed the way I look at software engineering forever.
Down the rabbit hole
I started thinking about what the gold standard of software quality is. My first answer was NASA. How does NASA solve these kinds of issues?
AI now produces so much code that I feel like I am losing ownership of it. Not only of the code. Of the intent.
I wanted to understand how people work when tests passing is still not enough and the price of being wrong is huge.
The surprising thing is that a lot of NASA’s work is public. Their software engineering requirements are public. FRET is public. Kind2 is public. A lot of the case studies are public. There are papers about aircraft, Mars rovers, superconducting magnets, and formal requirements that found bugs before code existed.
I started reading all of this not as an academic exercise, but because I had a very dumb practical problem: my tests were green, my coverage looked fine, and still one missed edge case was enough to create a public CVE.
Then I went deeper into automotive and aerospace. It opened a whole new world of software engineering for me. For some reason, our world of consumer software engineering and regulated software engineering in those industries almost do not intersect. Different tools, different conferences, different language. Sometimes it feels like they live in a parallel universe.
Some of it looks archaic. Some methodologies are weird.
Our engineering progressed a lot too. We got very good at moving fast and catching damage quickly. CI/CD, linters, tests, canaries, observability, rollbacks. I don’t want to pretend every SaaS product should behave like avionics certification.
But we optimized for speed. They optimized for evidence.
Their industry spends much more time asking what evidence they need before they are allowed to trust the change. Some of it is painful. Some of it is bureaucracy. But the idea underneath is not stupid: if you claim the system should behave in some way, you need a durable chain from that statement to tests, code, and evidence.
There is real proof there, but it is not the fantasy version I had in my head, where every line of every product is mathematically proven end-to-end. They prove specifications. They use model checking. They simulate models, like with Simulink, against many input/output cases. They measure structural coverage. They use formal proof where the criticality justifies it.
And they still use testing, code review, static analysis, and all the normal engineering work around it. The difference is that proof and evidence are attached to the parts where being wrong is not acceptable.
That actually made the idea useful for normal engineering.
This is a huge topic, which I will cover in future articles. But the first concrete thing I found was MC/DC. It is one of the ways safety-critical industries look at coverage, and it made standard line coverage look very weak to me.
Line coverage says a line was touched at runtime. It does not say that the decision was tested.
Why 90% line coverage can still mean 60% real coverage
I still use line coverage. I still look at it.
But line coverage is bullshit. You should not trust it. Not on its own.
In Go, when you run:
go test -cover ./...you mostly get statement coverage. The tool tells you whether a statement executed during the test run. That’s useful. But it doesn’t tell you whether the decision was tested.
Take a tiny parser-style example:
func isDigit(c byte) bool {
return c >= '0' && c <= '9'
}Now test it like this:
func TestIsDigit(t *testing.T) {
if !isDigit('5') {
t.Fatal("5 should be a digit")
}
if isDigit('x') {
t.Fatal("x should not be a digit")
}
}Looks fine. The line ran. The function returned true once. The function returned false once. Your coverage report can look perfect.
But what did you actually prove?
You tested '5'. You tested 'x'. You didn’t prove the lower boundary. You didn’t prove that '/' fails because it’s before '0'. You didn’t prove that ':' fails because it’s after '9'.
The line is covered. The boundary is not.
MC/DC stands for Modified Condition/Decision Coverage. It asks the question line coverage does not ask: did each condition independently affect the outcome?
When your code says if a && b, line coverage tells you the if was hit. MC/DC asks whether a alone can change the result, and whether b alone can change the result.
For this line:
return c >= '0' && c <= '9'there are two conditions:
c >= '0'
c <= '9'A simplified MC/DC table looks like this:
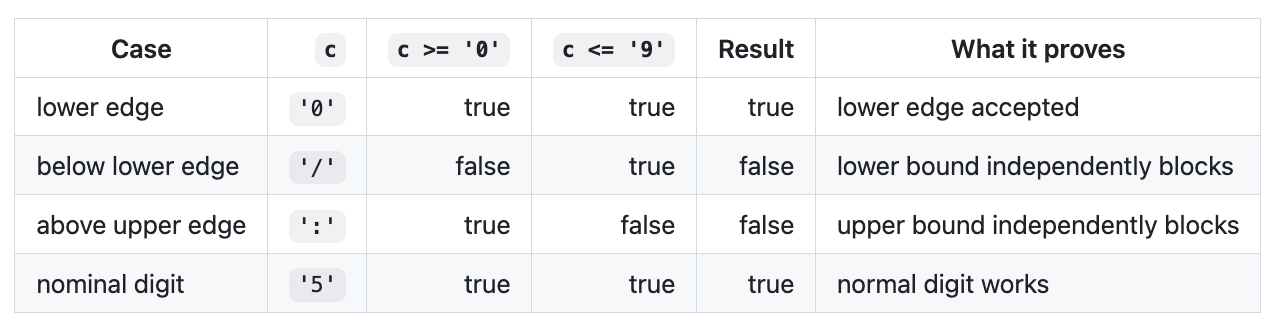
The table is just a way to say: these are the cases that matter. This is the part ordinary coverage does not force you to say.
This used to be mostly a safety-critical tooling conversation. DO-178C requires MC/DC for the highest-criticality aviation software. The tooling was expensive, slow, and hard for normal teams to justify.
That changed. GCC 14 has -fcondition-coverage. Clang 18 has -fcoverage-mcdc. Rust is moving in the same direction with richer branch and condition coverage work, even if I would not call Rust MC/DC stable yet. Go does not have native MC/DC support, so I ended up adding code-level Go MC/DC measurement to Proof, and we have been extending the same direction to JavaScript and TypeScript as well.
What aerospace and automotive had because they were slow and diligent is now becoming available to normal engineering teams because AI changed the economics. You don’t need a certification lab to ask a harder question about your tests. You also don’t need to apply all of this to the whole company on day one. Start with the part where wrong behavior actually hurts.
The jsonparser numbers weren’t subtle
After the CVE fix, I wanted to understand why my previous approach didn’t make this kind of missing behavior obvious enough.
So I applied the MC/DC and requirements approach to jsonparser in a later public PR: buger/jsonparser#281.
Again: this PR didn’t fix the original CVE. It was the follow-up work after the CVE fix. But it was not just a paperwork exercise. The hardening pass found and fixed more real issues and removed dead code that my previous process had not made obvious.
That was the uncomfortable part for me. I started by asking: what did my tests actually prove?
On the main branch before that work, ordinary Go statement coverage was already decent:
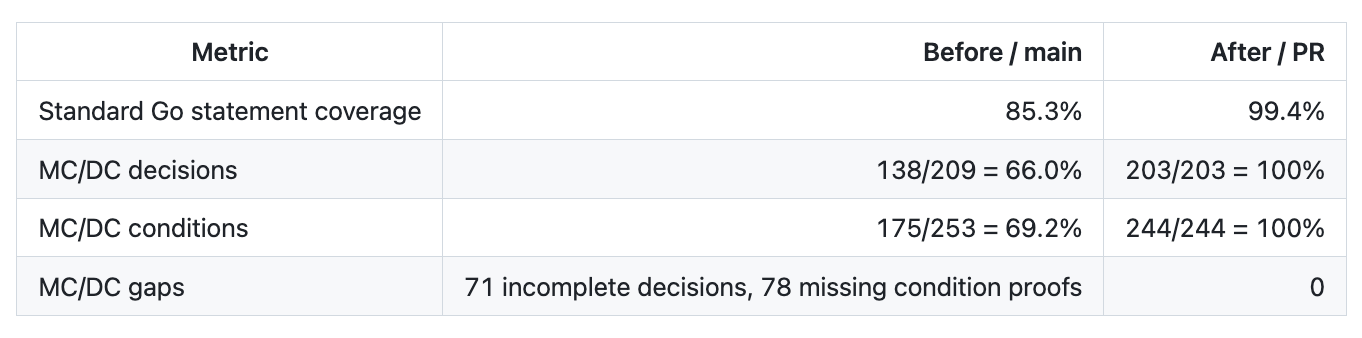
85.3% coverage isn’t bad. Most teams would see that and move on. But decision coverage told a different story: only 66% of decisions were fully covered, and only 69.2% of conditions were proven independently.
And the more interesting part: some functions already looked perfect by ordinary coverage.
Examples from the before state:
parseInt 100% statement coverage
Unescape 100% statement coverage
decodeSingleUnicodeEscape 100% statement coverage
But MC/DC still found missing independent-condition evidence:
bytes.go:21 parseInt missing proof for c < '0'
escape.go:148 Unescape missing proof for len(in) > 0
escape.go:47 decodeSingleUnicodeEscape missing proof for h1 == badHex
escape.go:47 decodeSingleUnicodeEscape missing proof for h2 == badHex
escape.go:47 decodeSingleUnicodeEscape missing proof for h3 == badHex
100% line coverage can still leave a condition unproven.
The code ran. The decision wasn’t tested.
The bug was in what I forgot to describe
Coverage does not paint the whole picture. Even MC/DC. The bug can still be in the spec.
That is what happened with jsonparser. It was a classical case: you are building something, moving forward, and not looking back. You don’t know what you don’t know. I did not think about what would happen if this edge case appeared. I think most of us do not think about it this way.
I did not have any specs driving development or anything that forced me to think about the edge cases before writing the code. So of course I did not test for them. You cannot test for what you never described.
Testing assumes the specification is correct. That is the NASA/formal-methods lesson that changed how I think about this. The hard part is not testing the implementation. The hard part is questioning the specification itself.
This is where I found two different questions that I had been mashing together.
The first question starts from my specification: if this is what I claim the system should do, which logical cases need to be witnessed?
Not the code. The intent.
NASA built an open-source tool called FRET (Formal Requirements Elicitation Tool) that lets you write requirements in structured English and translates them into formal logic.
FRET includes an algorithm called FLIP (FuLl Independence Pair). FLIP takes a formalized requirement and generates the minimum set of test cases proving each boolean variable independently affects the outcome. Not every possible combination. Just the ones that matter.
I still have to write the requirement. I still have to decide what malformed input, boundaries, errors, and edge cases mean. FLIP does not do that for me.
But once the requirement is formalized, FLIP tells me exactly which test cases that requirement needs.
I built a tool called Proof that implements this approach.
That is the part I care about: how many tests are enough for this requirement?
Not “how many tests did I happen to write?” Enough for what I described.
The second question starts from my actual code: did my tests exercise every boolean condition in the implementation so each one independently affects the outcome?
This side does not care what I meant. It looks at what I wrote.
And sometimes it shows that my code has many more logical cases than my spec. So maybe my spec is not accurate enough.
Or my spec says this edge case matters, but my tests don’t witness it.
Or my tests cover implementation details, but the behavior is under-described.
I learned this the hard way on jsonparser. The spec side and the code side kept disagreeing in useful ways, and that is where code drift and spec drift become visible.
The gap goes in both directions. Sometimes the code is wrong. Sometimes the tests are weak. Sometimes the spec is too vague.
Sometimes all of it combined badly.
Checklists, not memory
What can be more deterministic than a checklist? In aerospace and automotive, everything has its own checklist. The price of a mistake is too high to rely on someone’s memory. I think checklists are the driving force behind quality engineering in those industries.
When you do not have specifications, it is very hard to create a checklist. When you are building a feature, you can have test cases, but that is a moving target. The items are constantly changing. You need something that will be the same all the time.
In this context, an obligation is not a test case. It is a category of behavior you are required to describe. Malformed input is an obligation. Boundary behavior is an obligation. Error handling is an obligation. For each one that applies to your requirement, you need at least one test case that proves how the system behaves in that category. The obligation does not tell you the answer. It forces you to ask the question.
You cannot rely on humans here. Even on me, to be frank. I can miss these items too. You need deterministic checklists.
In practice, the questions are very simple:
What will happen if this is malformed data? What will happen if this is slow and the request times out? What will happen if the database is down? What will happen if you have a very large object? What will happen if the function returns different values with the same inputs?
These are the cases where security issues and data bugs tend to live. For jsonparser, these are the exact cases I had not thought about.
Without obligations, edge cases depend on memory. Maybe I remember to test malformed data. Maybe the AI remembers. Maybe a reviewer notices. Maybe no one does.
At the moment, it is just a matter of whether someone forgets or not forgets to test it.
This is where the CVE fix actually changed how I work. The fix itself was mechanical. But the obligations I wrote afterward forced me to think about the cases I had skipped. Every one of those became an explicit question I had to answer. Not “did someone remember to test this?” but “here is the list, and each item needs a witness.”
Obligations turn edge cases from “someone remembered to test this” into a deterministic process.
When I first started writing obligations for jsonparser, it was actually quite easy with modern AI tooling. I reviewed all of the specs. The flow is: you cannot pass this check until the checklist is green, until you define obligations for all of those cases, and until you define test cases for all of those cases as well.
This is what the double link looks like in practice:
// In the code — annotated with the requirement it implements:
// SYS-REQ-863
func (s *Service) lookupCache(req Request) (*Result, bool) {
// ...
}
// In the test — annotated with both the requirement AND the specific MC/DC row:
// Verifies: SYS-REQ-863
// MCDC SYS-REQ-863: cache_lookup_requested=T, component_inputs_unchanged=F,
// cached_component_result_reused=F => TRUE
func TestMCDC_SYS_REQ_863_Row1(t *testing.T) {
evalVerifyScenario(t, "SYS-REQ-863", map[string]bool{
"cache_lookup_requested": true,
"component_inputs_unchanged": false,
"cached_component_result_reused": false,
}, true)
}Each test is not just “test the function.” Each test is: “prove that this specific variable independently affects the outcome of this specific requirement.”
If I change the spec, I can see exactly which MC/DC rows are affected and which tests need to be reviewed. If I change a test, I can see which spec requirement it was proving and check whether the spec still says the same thing. If I add a new variable to the requirement, FLIP will generate new witness rows, and the missing tests become immediately visible.
This is the double link. Change the spec, review the tests. Change the tests, review the spec. If you have not touched the spec, why would you touch the test?
This is where the “how many tests are enough?” question changed for me. Before, the answer was always vibes. Write enough tests. Cover important paths. Don’t overdo it. Be pragmatic.
All true, and also not very helpful.
Now I think about it differently. Enough tests means enough evidence that every condition I described, or every condition my code actually contains, can independently affect the behavior I care about.
It is not about how many tests I have. It is about whether I really, really trust my system and whether it actually does what I described.
The true challenge is legacy
You can always start a new project and have a really nice experience with all of this. But the true challenge lies in the big legacy projects. They make up like 90% of all software. They bring the majority of the money. And they are the ones where wrong behavior actually hurts.
I work with very complex software. At Tyk, we build API gateway software used by banks, governments, and other serious enterprise customers. I am a very sceptical person. I always want some proof. At the same time, I understand that software is always about compromises.
But the game is changing. What was not possible in the past is now possible for small teams in terms of quality and processes. The wind is changing with AI.
The true power happens when you can apply some of those approaches to legacy large enterprise codebases. If it works there, it will work everywhere.
I know how challenging it is. You cannot do it in one go. You cannot just make a switch and start using a new process.
This is not only about the technical part. It is also about the people part. Even at the size of Tyk, with like a hundred people, it is not about the implementation. It is about the processes and the people. The technical part is the easiest one.
In order to convince people that you can actually make it, you need to be able to do it in parts. Start small, then scale.
Can you take small parts, turn them into a repeatable process, and then start scaling? That is how it works in the majority of cases.
So I picked the policy engine. Authorization and gateway policy decisions are obviously critical. If the policy engine behaves incorrectly, you are not talking about a cosmetic bug.
I applied the same kind of thinking to the Tyk policy package in a public PR: TykTechnologies/tyk#7932.
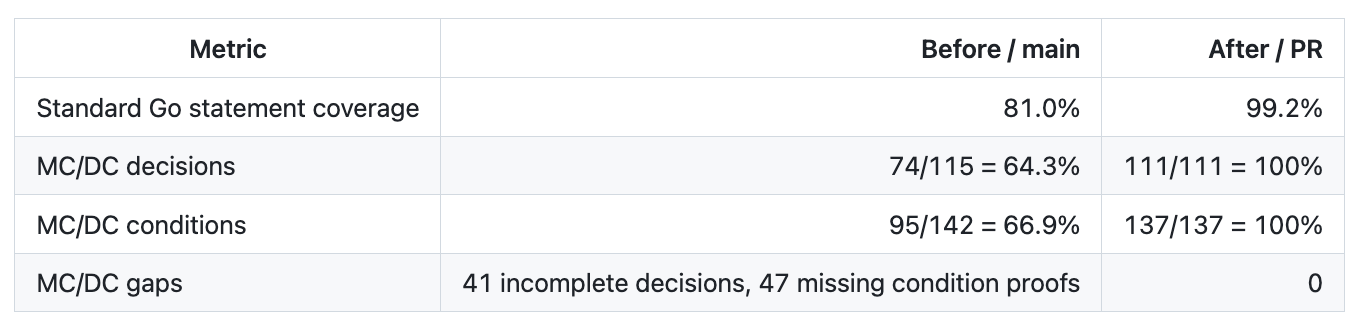
81% ordinary coverage. 64.3% decision coverage. The normal coverage number says most statements ran. The MC/DC number says a lot of policy decisions still do not have independent evidence.
For a policy engine, the second number is the one I care about.
Code coverage is not about a metric
It is about trust.
What do we trust? In classical software engineering, we say: here is the code and here are the tests, the tests are the source of truth. If you want to know how the system works, read the tests.
I do not believe that anymore. Not with AI writing code. Not with AI writing tests. Not with AI validating its own assumptions.
The source of truth cannot just be tests anymore. AI can write those too.
A passing test can prove that the code agrees with the test. It cannot prove that both agree with my intent.
So I moved the source of truth up. For me, it has to be the specification: the static description of what I expect the system to do.
Then code implements it. Tests witness it. Coverage measures evidence around it. Traceability keeps the chain from silently rotting.
I started this whole journey because of one CVE in a library I wrote six years ago. I ended up in a completely different place.
I thought the problem was in the code. It was in what I forgot to describe.
I thought coverage was the answer. It was the wrong question.
The first article was about losing intent. This one is about binding intent back to code.
Great essay. Everything you've named (spec as source of truth, MC/DC over line coverage, obligation checklists, traceability against rot) is necessary.
It's also insufficient. The instrument defines what's visible: coverage tooling, test methodology, and audit framework each creates a "cone of illumination", and bugs outside that cone are invisible by construction, not by oversight. Even a perfect spec doesn't survive contact with code whose architecture forecloses the necessary verification itself.
"You cannot test for what you never described" is one version of the cone problem. The deeper version: tests cannot catch conditions that by construction can only be evaluated at runtime. The spec-vs-code verification step itself becomes impossible when "what does this do?" is a runtime question rather than a property of the inputs.
The architectural challenge is constructing code so every condition within spec is definitively predictable by example bounds. That's a construction-time choice that cannot be retrofitted at test time. The studliest version of the NASA approach is exactly this: not exhaustive testing, but architecture that makes whole categories of test unnecessary. My proposed architectural discipline called Honest Code operationalizes it, with the Honest Framework as its FOSS reference implementation. Anyone telling you it's ineluctable, that some code just has to be runtime-opaque, is wrong.
I also developed the Slop Audit to detect this type of failure: 18 architectural dimensions backed by 20 quantitative Layer-1 indicators, each with a layered procedure, designed so the auditor's judgment is bounded by the framework rather than by personal or professional opinion. Same instinct as MC/DC + FRET/FLIP, applied to architectural conditions rather than boolean ones.
Its most provocative indicator is L1.18, the Mutable State Ratio: the percentage of functions that read or write state outside their parameter list. The claim isn't soft. L1.18 measures the proportion of code that is mathematically untestable regardless of test budget, because mutable-state systems are subject to state-space explosion that no finite test suite can cover. It's also a defect-category predictor: race conditions, order-dependent test failures, stale-cache bugs, side-effect interference, and null-from-uninitialized-state are all confined to at most the L1.18 percentage of functions. At L1.18 = 0%, every function's behavior is a finite function of its parameters and prediction is exact. Your jsonparser had near-perfect line coverage and missed an unasked spec question; L1.18 catches an adjacent failure mode where the question can't be answered with any test, because the code's shape forecloses every test you could write.
An ongoing pre-registered experiment (DOI 10.17605/OSF.IO/DBSYG) tests whether AI code-generation accuracy depends on this same architectural property: three frontier models, twenty-five programming tasks, five paradigm conditions. The prediction is that construction-style paradigms (low L1.18) outperform class-heavy ones (high L1.18); the pre-registration is what makes that prediction falsifiable rather than retrofitted.
The economics shift you named (AI lowering the cost of MC/DC) applies in the other direction too: AI lowered the cost of construction methodologies. What once required a NASA-grade requirements process is now reachable for any disciplined team.
Happy to share the pre-release auditing code that calculates L1.18 if you want to try it on jsonparser. The code has already been run on itself, of course :)